


Being a MuleSoft subject matter expert (SME) requires a lot of learning and knowledge retention. You need to understand Java, operating systems, networking, and cloud infrastructure. You need to know how to troubleshoot integrations with dozens of different vendors and their connectors. And you need to understand APIs end-to-end – from design and implementation all the way through to runtime and monitoring.
Building that breadth of knowledge takes time. Becoming an SME in even one area takes time. And when you need help, finding the right SME – the one who knows that specific product, that specific edge case, and is available 24/7, is a difficult problem to solve.
For a complex case that spans multiple products or technologies, it’s difficult to connect all the dots and be confident you have the right knowledge to move forward. Beyond the official documentation and known issues, our team has accumulated a wealth of knowledge over the years: knowledge articles, internal knowledge transfers, training materials, troubleshooting guides, and more. But locating the right piece of information across all of that, at the moment you need it, has always been a challenge.
When an engineer gets stuck, we have a process called swarmingwhich entails posting a Slack thread and to alert a senior team member or SME to weigh in. But that wait depends entirely on who’s available and who has the right expertise. Even before reaching that point, just doing initial triage on a complex case means manually checking up to 12 sources:
- OrgCS Cases
- CIS
- Knowledge Articles
- Ideas
- Known Issues
- GitHub
- Slack
- Confluence
- Docs
- Release Notes
- Quip
Toggling between all these different sources takes between 30 minutes to a couple of hours for complex cases. Behind all those sources sits an enormous body of knowledge: 9,500+ documentation pages, 4,400+ knowledge articles, 2,300+ known issues, and 800+ internal Google Drive files with recordings, slide decks, troubleshooting guides, and more.
The right answer almost always existed somewhere. The problem was finding it.
But this wasn’t our first attempt to solve this problem. We first built a keyword-based search engine to help engineers navigate our internal knowledge. Then, as LLMs became available, we explored using Gemini directly on Google Drive. Both moved the needle — especially with LLMs, the shift from keyword matching to semantic search using natural language was a real step forward.
But each solution only solved part of the problem. What we really needed was a system that could consolidate knowledge scattered across different sources, understand the intent behind a question, and route intelligently to the right source to find the right answer — all in one step.
We believed AI could do that now, and we found the right solution to make this vision a reality.
Enter MuleSoft Agent Fabric
At Salesforce, we have a strong track record of using our own products to improve the customer support experience. The journey starts with Agentforce for Salesforce Help, where customers can self-serve. This gives our support team the ability to focus on more complex and high-touch support requests. So the question became, how do we continue to use our own products to further improve time to resolve on a case?
At the right time, we saw the right solution. MuleSoft Agent Fabric could do exactly what we wanted.
Agent Fabric is MuleSoft’s agent control plane. It’s designed to help organizations discover, govern, and orchestrate AI services across their entire technology ecosystem. With the Agent Broker, the intelligent orchestrator, you can plug in modular knowledge tools from any source and define precise rules for routing should happen.
We turned our knowledge sources (MuleSoft Docs, Known Issues, Knowledge Articles, and our internal Google Drive) into MCP servers and connected them via an Agent Broker. Then we gave it routing rules tailored to the types of questions support engineers actually ask:
| Question type | Routing logic |
|---|---|
| “What is X?” | Docs MCP |
| “How do I do X?” | Docs MCP + Knowledge Articles MCP |
| “There’s an issue with X” | Known Issues MCP first, then Knowledge Articles MCP |
| “How do I troubleshoot X?” | Google Drive MCP + Knowledge Articles MCP |
With those instructions in place, Agent Broker understands the incoming question, applies the right routing logic, queries the appropriate knowledge sources, and synthesizes a grounded answer in 20–30 seconds, complete with referenced source links. But Agent Fabric didn’t just solve the coordination problem. It also solved the “trust” problem.
Trust is our number one value
At Salesforce, trust is our number one value, and in support, that means we can’t allow customer PII to flow into an LLM. Support engineers regularly work with customer-provided logs, which can contain email addresses, phone numbers, and other sensitive data. Agent Fabric addresses this with a native PII detection policy that can be applied at both the agent level and the MCP server level:
- A2A PII Detector Policy scans requests sent to the agent and can be configured to log or block when PII is detected (email addresses, SSNs, credit card numbers, phone numbers)
- MCP PII Detector Policy blocks responses containing PII from reaching MCP servers, reporting a policy violation and declining the request
On top of that, authentication and rate limiting policies are applied through Omni Gateway at ingress, ensuring the platform is secure, compliant, and accessible only to the MuleSoft Support team. Governance wasn’t an afterthought. It was built in from day one.
References: MCP PII Detector Policy | A2A PII Detector Policy
How Our AI Support System Works
We named the system Hive. It’s available to every MuleSoft Support engineer globally through two interfaces.
Via Slack, where answers arrive in 20–30 seconds with referenced source links:
- @mention Hive in any Slack channel or thread, or open the Hive app directly for a private conversation:
- @Hive What are the troubleshooting steps for Anypoint MQ message loss?
Via Claude Code (cursors, etc.):
- Ask any MuleSoft-related question naturally in Claude — it automatically routes the question to Hive via MCP: How do I configure client ID enforcement on API Manager?
- Or ask explicitly:
- Ask Hive about DataWeave transformation performance best practices
Hive works best when you ask natural questions about MuleSoft topics. Under the hood, the system runs across four layers:

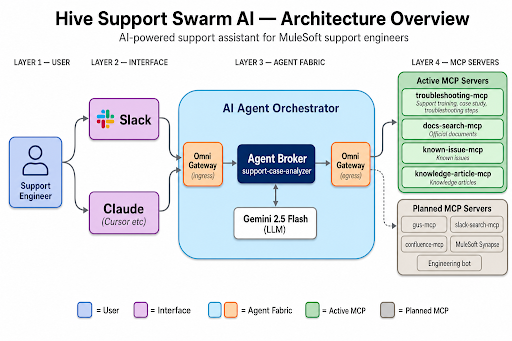
While Hive’s MCP servers currently run on Google Cloud using the Python FastMCP SDK, they can equally be implemented as Mule applications using MuleSoft’s native MCP connectors, making the architecture fully portable within Anypoint Platform.
Built by the people closest to the problem
Hive went from concept to production in roughly three months with the Claude Code integration live on May 1, 2026 and the Slackbot on May 15, 2026.
This was not a funded initiative. There was no dedicated engineering team, no sprint allocation, no hackathon brief. It started with a conviction Zach AbrahamVP of MuleSoft Support — that the people closest to the problem are best positioned to solve it. Zach didn’t just sign off on the idea. He actively sponsored the team with time, helped get internal review and approval, cleared the organizational path, and gave the team the confidence to pursue something ambitious alongside their day jobs.
A small group of support managers and engineers built Hive while continuing their full-time responsibilities. They turned a daily frustration into a passion project — and that passion project into a production AI system running on Salesforce’s own platform. Hive is part of a broader wave of innovation happening inside MuleSoft Support right now — the team is running a hackathon that’s already producing more ideas like this, and we’re just getting started.
The hard part: Earning quality
Shipping Hive wasn’t just a matter of connecting the tools. Quality had to be earned.
Lesson 1: Functional isn’t the same as accurate
Our pre-launch evaluation used 59 real historical swarm requests. Every single question got an answer. But when SMEs reviewed those answers for accuracy and grounding, only 10 passed — a quality rate of just 17%. We traced the failures to two root causes: insufficient context reaching the agent, and imprecise question-to-source mapping.
What followed was 28 rounds of iterative testing — refining prompts, improving MCP server responses, and strengthening our test data — until we reached a quality bar we were confident in. By Round 28, Hive was scoring 0.82 overall quality with 85% actual accuracy (46 out of 54 questions passing SME review).
Lesson 2: Fine-tune instructions and consider architectural best practices
When we added a fifth MCP server, answer quality dropped. Too many tools created routing confusion — the agent would select the wrong source, miss higher-priority ones, or blend generic results with a specific Known Issue it hadn’t actually retrieved.
We fixed this by rewriting our routing instructions. We recommend considering the multi-level hierarchical design pattern explained by our architects. Now we’re partnering with the MuleSoft product team to introduce parallel MCP execution into a future release of the Agent Broker.
The results
The numbers are still early, but they’re striking. We’re actively tracking these KPIs over the coming months — the projections below represent our current trajectory, and we’ll have a fuller picture by end of year.
- ~150 MuleSoft support engineers using Hive globally in MuleSoft Support
- ~200 queries per day in active use
- 30-40 minutes saved per case on initial research alone
- Swarm wait time: from hours → under 1 minute
- Projected 12-15% reduction in time to resolve by end of year
- Projected 30% increase in throughput (cases resolved per engineer per day) by EOY
Across the team, we’re seeing engineers actively share how they’re using Hive — in case research, in live chat sessions with customers, to surface relevant documentation and known issues quickly, and to cross-reference information so they know which direction to take a troubleshooting path.
Nobody waits hours for a swarm response anymore. The help they need is available in under a minute. One impact that doesn’t show up neatly in a dashboard. Language is no longer a barrier. Our Japan support team can ask questions in Japanese and receive accurate, grounded answers instantly.
What’s next?
Hive is a platform, not a finished product. The planned MCP servers will progressively expand the knowledge Hive can draw from. We’re also looking forward to leveraging the new guided deterministic patterns introduced via Agent Script with the next Agent Broker release in June 2026.
The longer-term vision is a self-sustaining system — one that doesn’t just answer questions from existing knowledge, but continuously concludes new knowledge and builds skills automatically, getting smarter the more the team uses it. This architecture isn’t limited to MuleSoft Support. Agent Broker is a modular, plug-and-play framework. The same pattern can be applied to any support organization — including Salesforce Support at large.
Try it out
AI is moving fast, and the best time to start is now. But choosing the right platform matters. Pick one that’s easy to build on and easy to govern.
MuleSoft Agent Fabric works with any MCP server, and as we demonstrated here, that includes non-MuleSoft ones. Security and compliance policies plug in natively. You don’t need a dedicated AI team to get started. You need the right framework and the people who understand the problem best.
Give it a try and share your ideas on how you’d build a support agent for your own organization. We’d love to hear from you. The best innovations always come from the people closest to the work. Explore MuleSoft Agent Fabric to get started. Have questions about Hive or want to learn more? Reach out to the MuleSoft Support Engineering team.